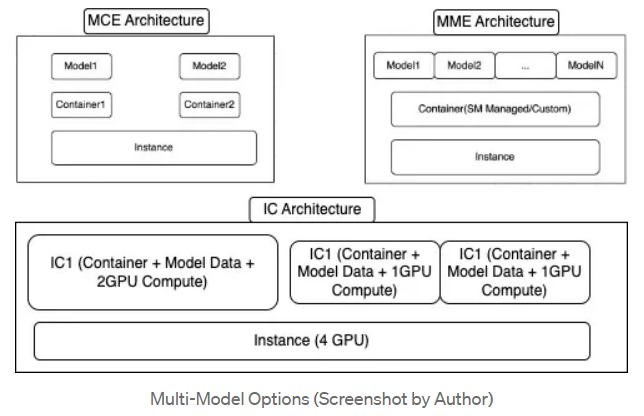
The IntelligentGraph capability is when intelligent agents can be embedded in an RDF graph. These agents are activated only when the graph is queried for results referencing the agent.
Link
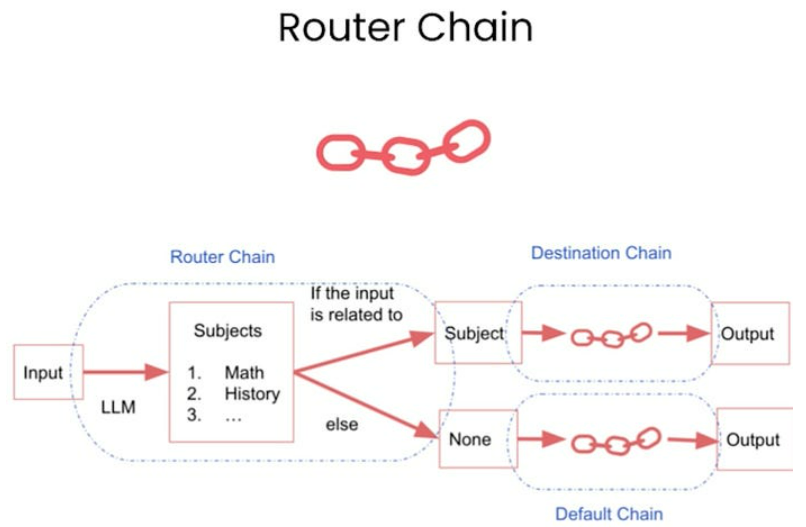
Use routes to remind agents of particular information or routes (we will do this in this notebook). Use routes to act as protective guardrails against specific types of queries.
Link
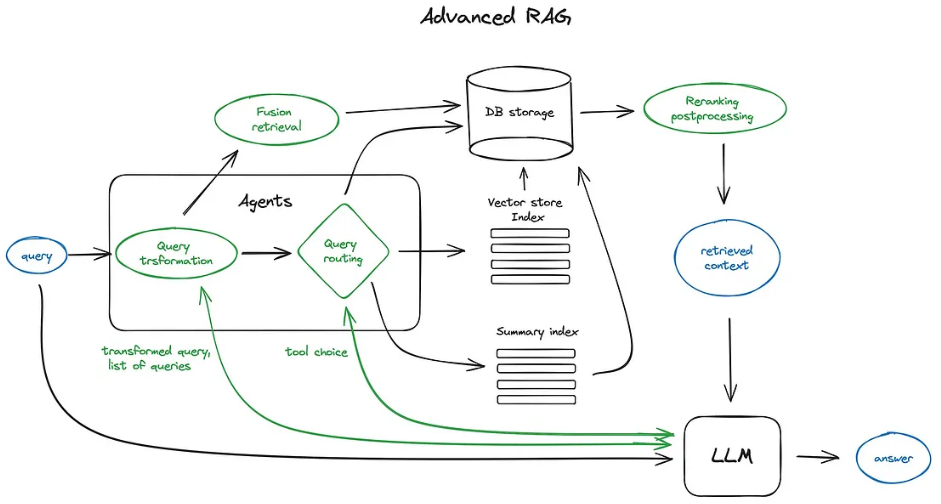
Today we introduce Query Pipelines, a new declarative API within LlamaIndex that allows you to concisely orchestrate simple-to-advanced query workflows over your data for different use cases (RAG, structured data extraction, and more).
Link
Usage Pattern
Example code for building applications with LangChain, with an emphasis on more applied and end-to-end examples than contained in the main documentation.
Link
LangChain Templates are the easiest and fastest way to build a production-ready LLM application. These templates serve as a set of reference architectures for a wide variety of popular LLM use cases. They are all in a standard format which make it easy to deploy them with LangServe.
Link
GitHub
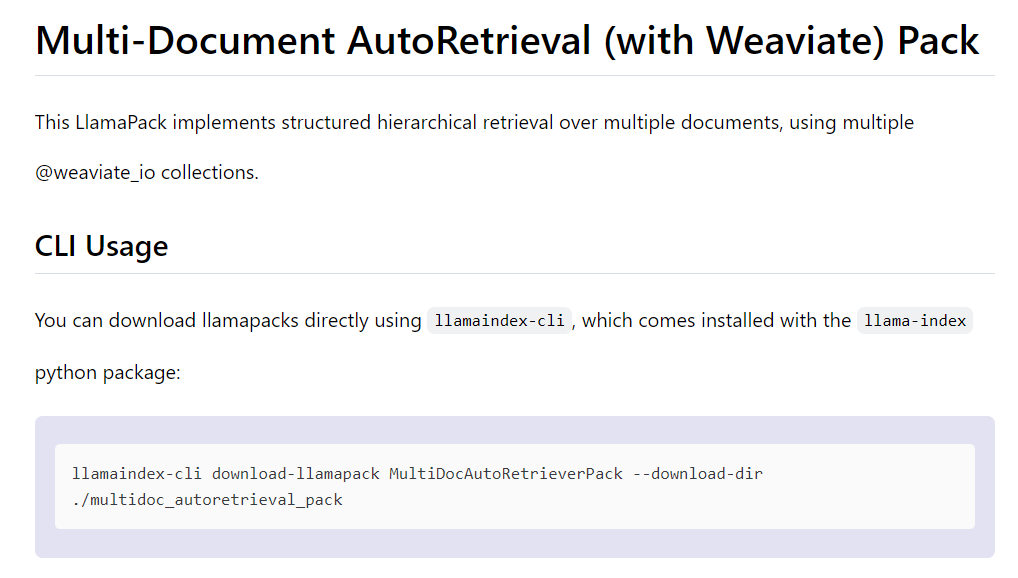
Get your RAG application rolling in no time. Mix and match our Data Loaders and Agent Tools to build custom RAG apps or use our LlamaPacks as a starting point for your retrieval use cases.
Link
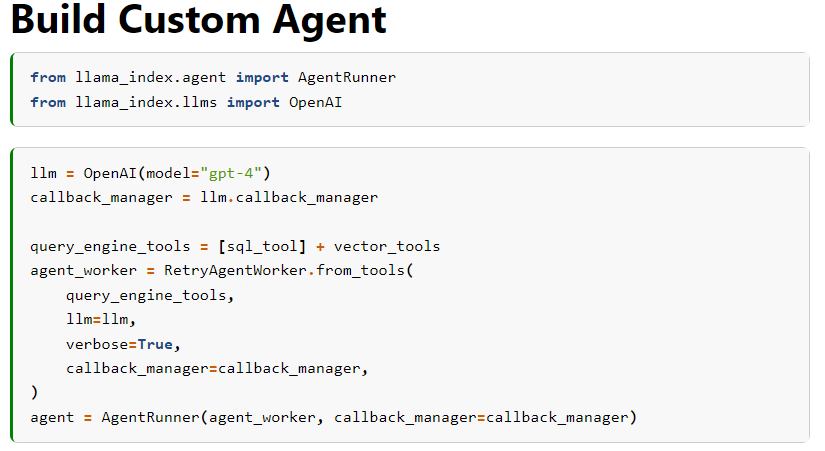
We show you how to build a simple agent that adds a retry layer on top of a RouterQueryEngine, allowing it to retry queries until the task is complete. We build this on top of both a SQL tool and a vector index query tool. Even if the tool makes an error or only answers part of the question, the agent can continue retrying the question until the task is complete.
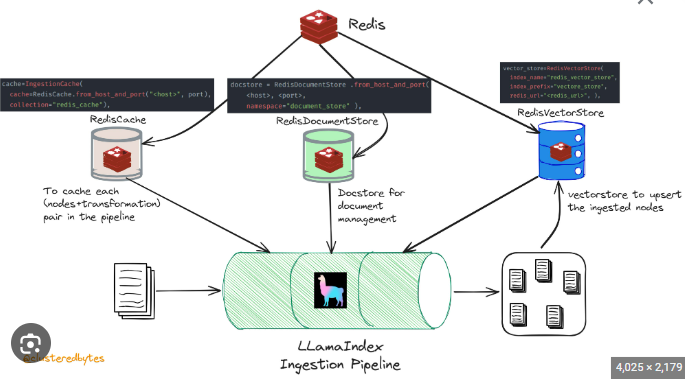
An IngestionPipeline uses a concept of Transformations that are applied to input data. These Transformations are applied to your input data, and the resulting nodes are either returned or inserted into a vector database (if given). Each node+transformation pair is cached, so that subsequent runs (if the cache is persisted) with the same node+transformation combination can use the cached result and save you time.
Link
LlamaPack
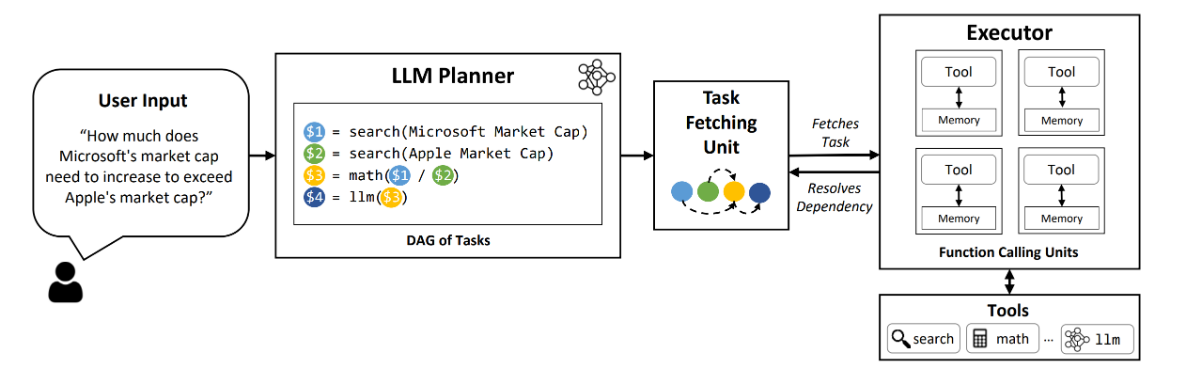
LLMCompiler is a framework that enables an efficient and effective orchestration of parallel function calling with LLMs, including both open-source and close-source models, by automatically identifying which tasks can be performed in parallel and which ones are interdependent.
[Link]{https://github.com/SqueezeAILab/LLMCompiler}
LLM Compiler Agent Cookbook
In the intricate landscape of modern software development, orchestrating complex sequences of actions seamlessly poses a significant challenge. Enter LangChain Expression Language (LCEL), a groundbreaking declarative approach designed to revolutionize the composition of chains within software architecture.
Link