Machine learning is a field of artificial intelligence (AI) that is concerned with learning from data. Machine learning has three components:
Supervised learning: Fitting predictive models using data for which outcomes are available.
Unsupervised learning: Transforming and partitioning data where outcomes are not available.
Reinforcement learning: on-line learning in environments where not all events are observable. Reinforcement learning is frequently applied in robotics.
Posts on machine learning
In the following posts, machine learning is applied to solve problems using R.
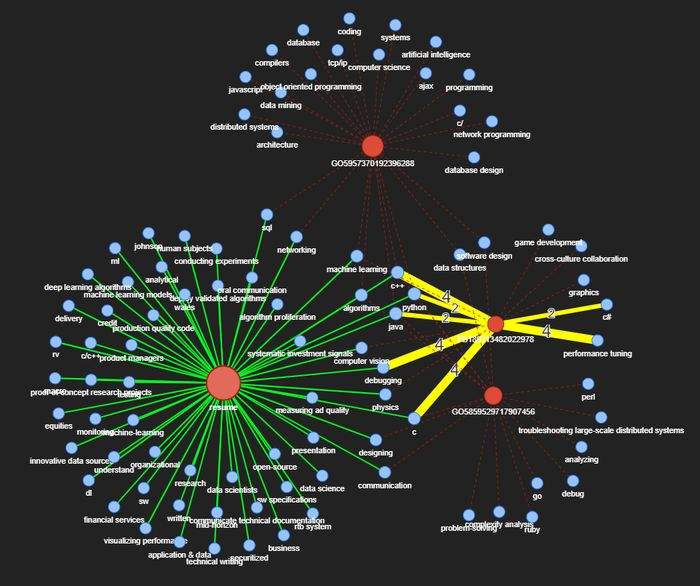
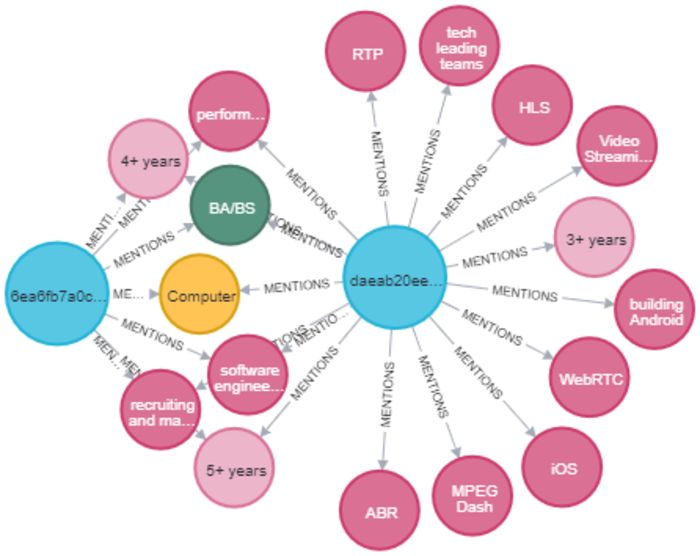
In this tutorial, we will build a job recommendation and skill discovery script that will take unstructured text as input, and will then output job recommendations and skill suggestions based on entities such as skills, years of experience, diploma, and major.
We will extract entities and relations from job descriptions using the BERT model and we will attempt to build a knowledge graph from skills and years of experience.
Link
How to build a knowledge graph from job descriptions using fine-tuned transformer-based Named Entity Recognition (NER) and spacy’s relation extraction models. The method described here can be used in any different field such as biomedical, finance, healthcare, etc.
Below are the steps we are going to take:
Load our fine-tuned transformer NER and spacy relation extraction model in google colab
Create a Neo4j Sandbox and add our entities and relations
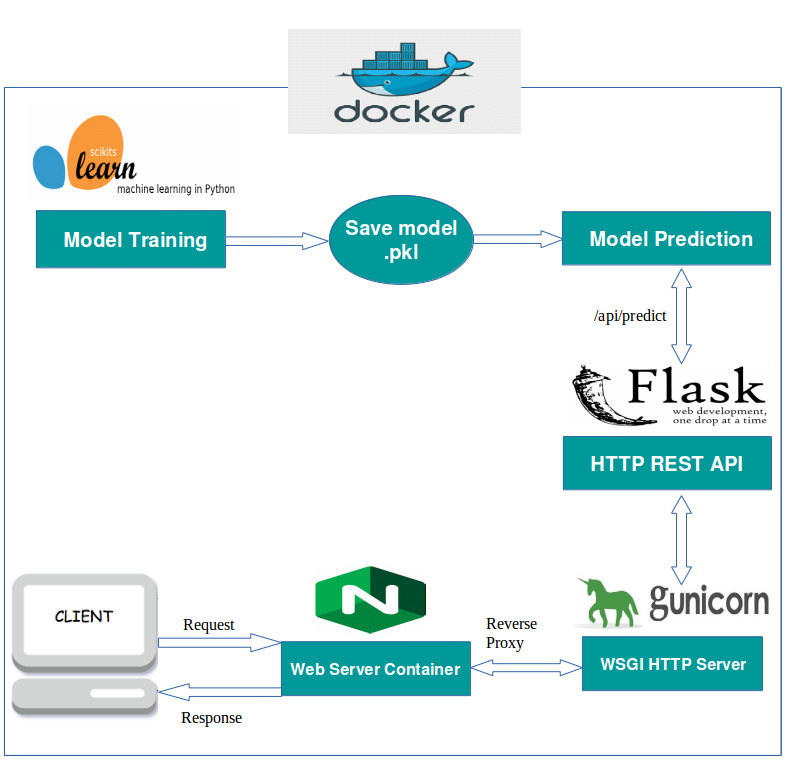
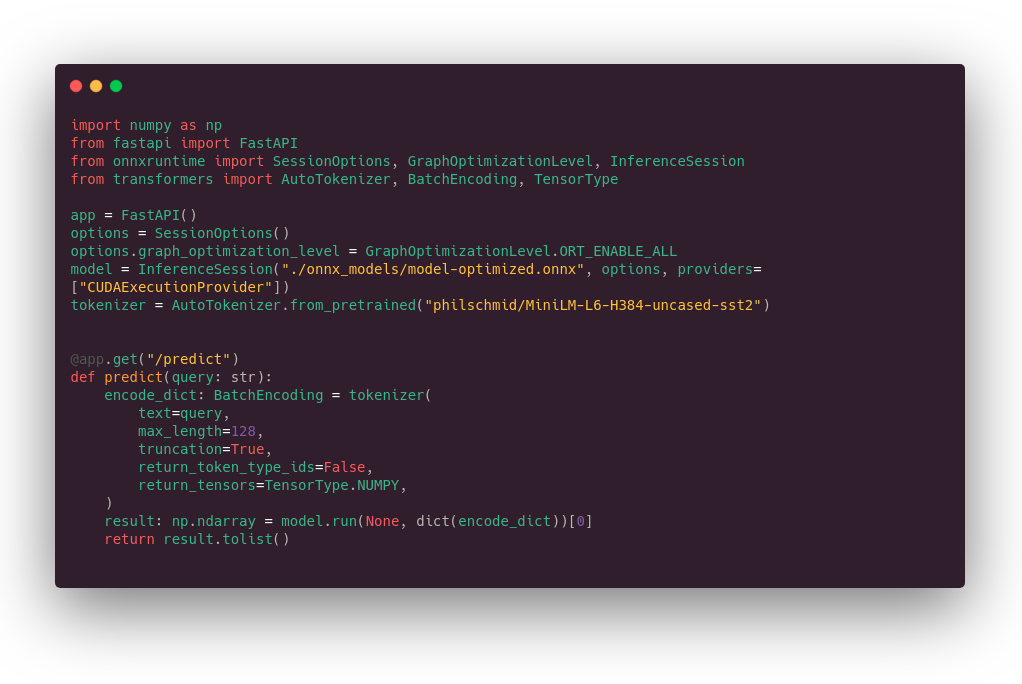
FastAPI might be able to help. FastAPI is FastAPI is a web framework for building APIs with Python. We will use FastAPI in this article to build a REST API to service an NLP model which can be queried via GET request and can dole out responses to those queries.
For this example, we will skip the building of our own model, and instead leverage the Pipeline class of the HuggingFace Transformers library.
Metaflow is a human-friendly Python library that helps scientists and engineers build and manage real-life data science projects. Metaflow was originally developed at Netflix to boost the productivity of data scientists who work on a wide variety of projects from classical statistics to state-of-the-art deep learning.
Metaflow provides a unified API to the infrastructure stack that is required to execute data science projects, from prototype to production.
Link
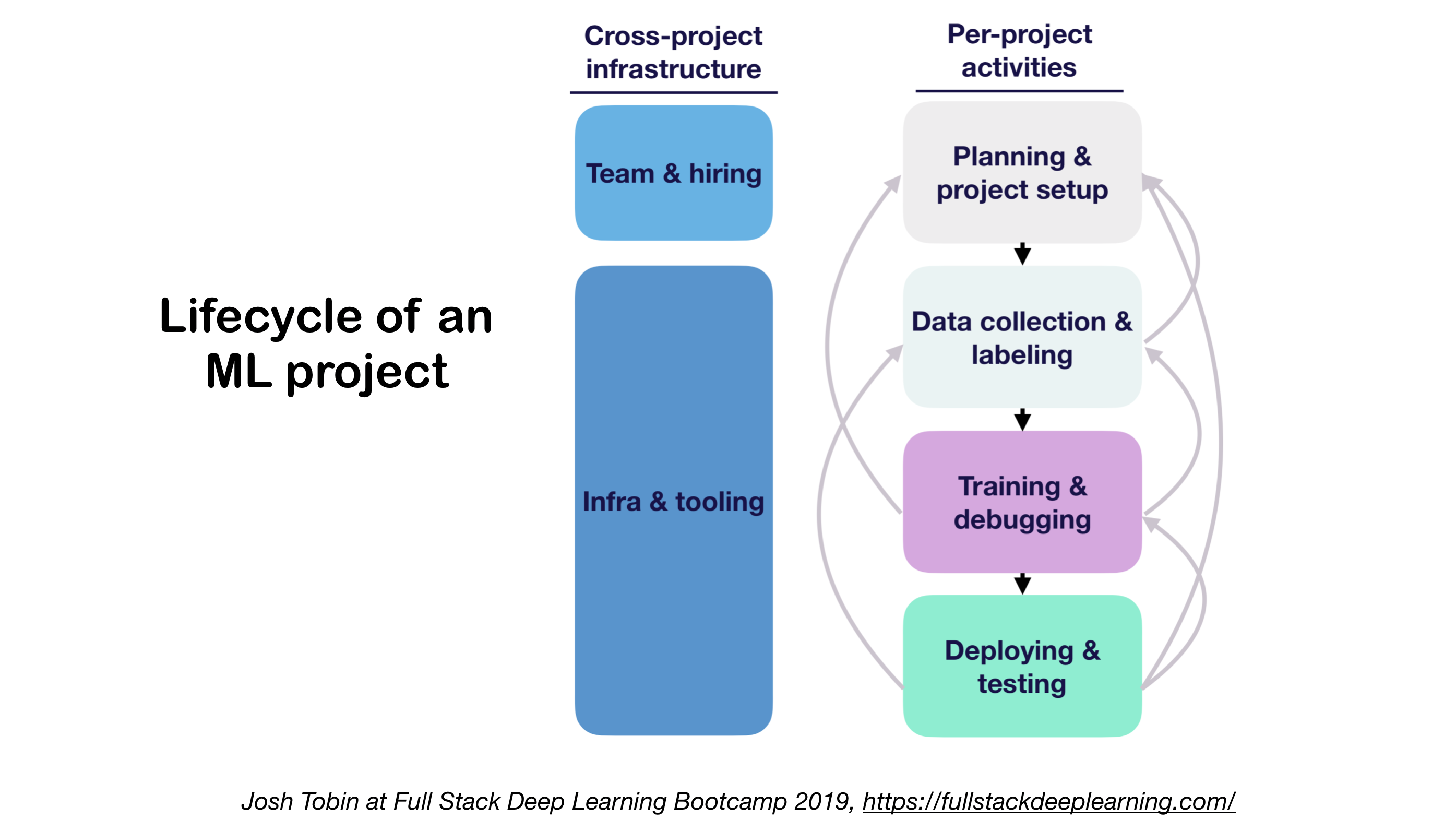
Deploying deep learning models in production can be challenging, as it is far beyond training models with good performance.
Several distinct components need to be designed and developed in order to deploy a production level deep learning system (seen below):
Link
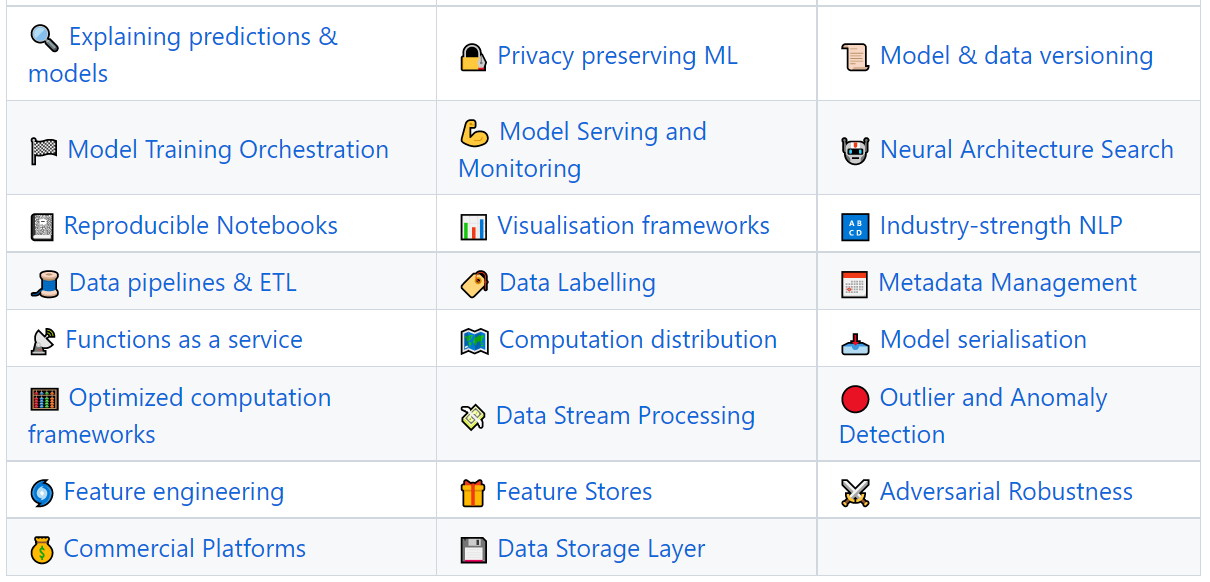
This repository contains a curated list of awesome open source libraries that will help you deploy, monitor, version, scale, and secure your production machine learning.
Link
Software Engineering for Machine Learning are techniques and guidelines for building ML applications that do not concern the core ML problem – e.g. the development of new algorithms – but rather the surrounding activities like data ingestion, coding, testing, versioning, deployment, quality control, and team collaboration.
Good software engineering practices enhance development, deployment and maintenance of production level applications using machine learning components.
Link
Write ML Pipelines that will make your MLOps team happy: follow a clean separation of responsibility between model code and ops code. This article show you how to do that.
Link
EvalML is an AutoML library which builds, optimizes, and evaluates machine learning pipelines using domain-specific objective functions.
Key Functionality
Automation - Makes machine learning easier. Avoid training and tuning models by hand. Includes data quality checks, cross-validation and more.
Data Checks - Catches and warns of problems with your data and problem setup before modeling.
End-to-end - Constructs and optimizes pipelines that include state-of-the-art preprocessing, feature engineering, feature selection, and a variety of modeling techniques.
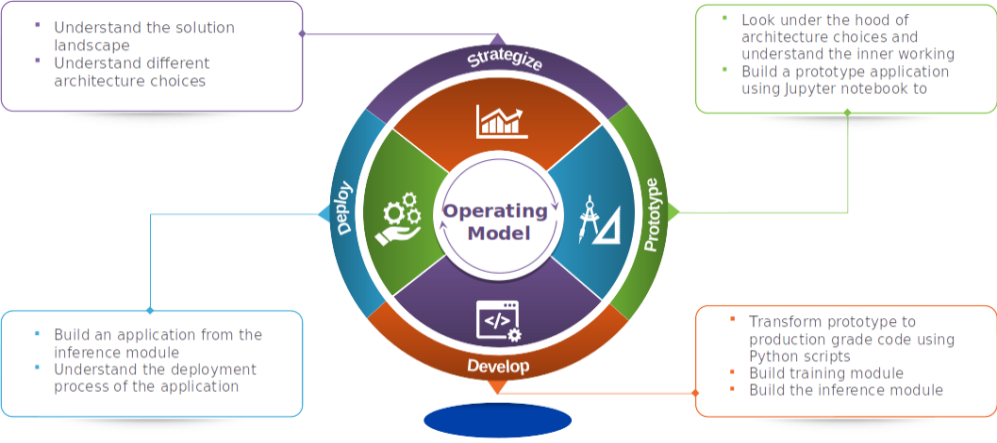
Build and Deploy Data Science Products : A Practical Guide to Building a Machine Translation Application This journey is going to be a 8 steps.
In this series we will take a use case, understand the solution landscape and its evolution, explore different architecture choices, look under the hood of the architecture to understand the nuts and bolts, build a prototype, convert the prototype into production ready code, build an application from the production ready code and finally understand the process for deploying the application .