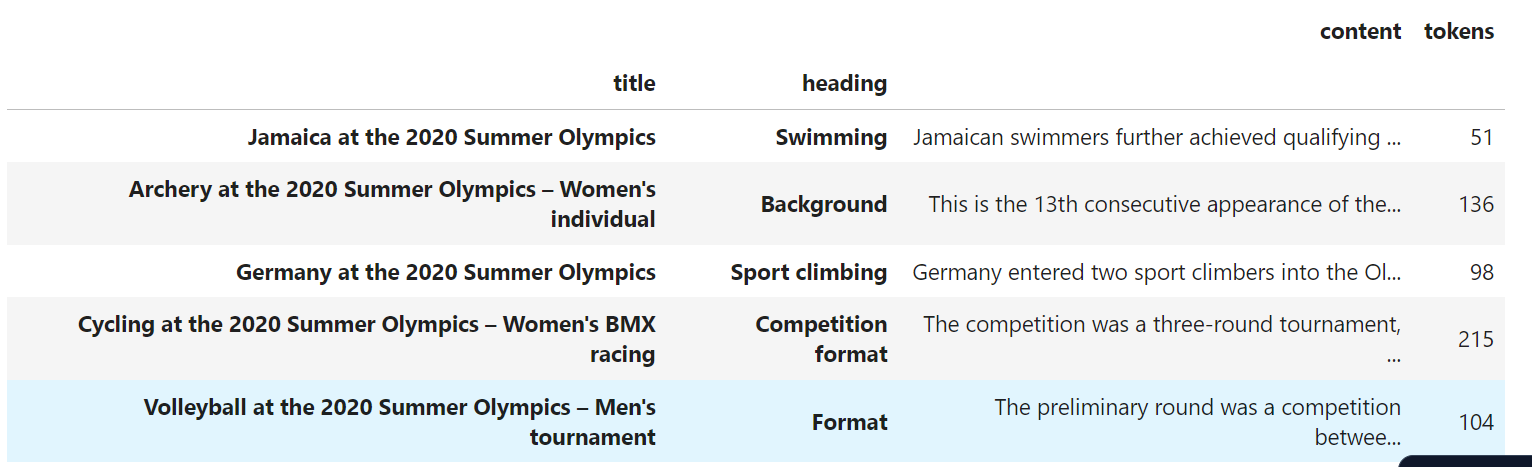
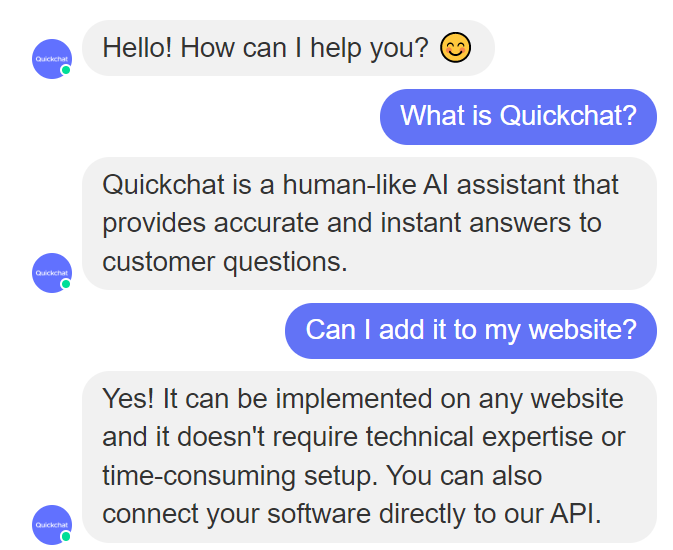
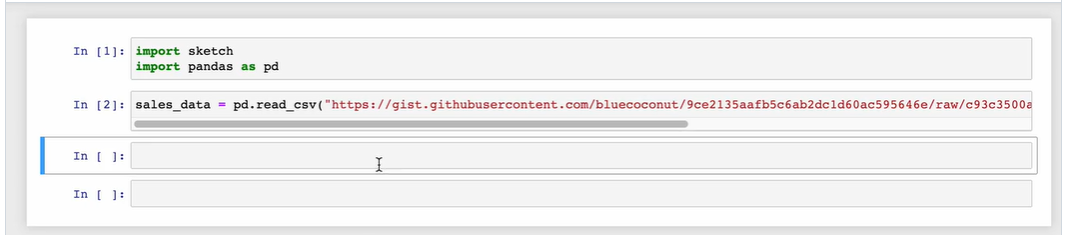
Many use cases require GPT-3 to respond to user questions with insightful answers. For example, a customer support chatbot may need to provide answers to common questions. The GPT models have picked up a lot of general knowledge in training, but we often need to ingest and use a large library of more specific information.
Link
Examples
The Large Language Model revolution started with the advent of transformers in 2017. Since then there has been an exponential growth in the models trained. Models with 100B+ parameters have been trained. These pre-trained models have changed the way NLP is done. It is much easier to pick a pre-trained model and fine-tune it for a downstream task ( sentiment, question answering, entity recognition etc.. ) than training a model from scratch.
Sketch is an AI code-writing assistant for pandas users that understands the context of your data, greatly improving the relevance of suggestions. Sketch is usable in seconds and doesn’t require adding a plugin to your IDE.
Link
Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.
Link
CopyMonkey generates and optimizes Amazon listings in seconds. AI helps place all of the important keywords in your Amazon listing to get you ranking organically on the first page.
Link
This year, we see significant progress in the field of generative models. Stable Diffusion 🎨 creates hyperrealistic art. ChatGPT 💬 answers questions to the meaning of life. Galactica 🧬 learns humanity’s scientific knowledge but also reveals the limitations of large language models.
Link
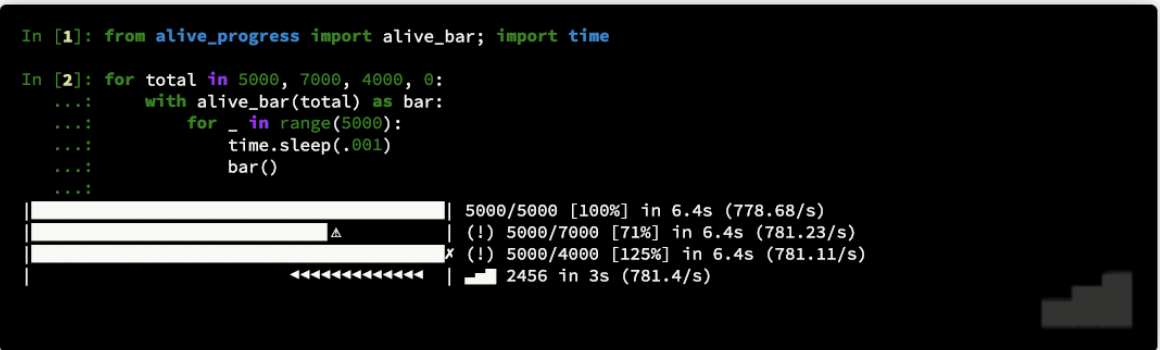
Have you ever wondered where your lengthy processing was, and when it would finish? Ever found yourself hitting [RETURN] now and then to ensure it didn’t hang, or if, in a remote SSH session, the connection was still working? Ever needed to pause some processing for a while, return to the Python prompt for a manual inspection or fixing an item, and then resume the process seamlessly?
Link
Aqueduct gives you a simple Python-native API to define machine learning pipelines, the ability to deploy those pipelines on your existing infrastructure (e.g., Spark, Kubernetes, Lambda), and visibility into the code, data, and metadata associated with your workflows. Aqueduct is fully open-source and runs securely in your cloud.
Link
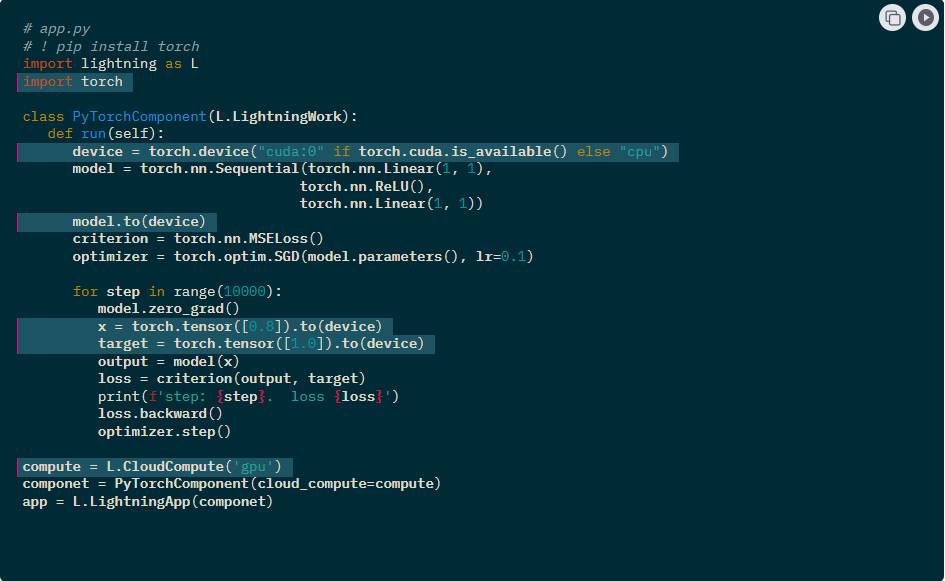
Use Lightning, the hyper-minimalistic framework, to build machine learning components that can plug into existing ML workflows. A Lightning component organizes arbitrary code to run on the cloud, manage its own infrastructure, cloud costs, networking, and more. Focus on component logic and not engineering.
Link