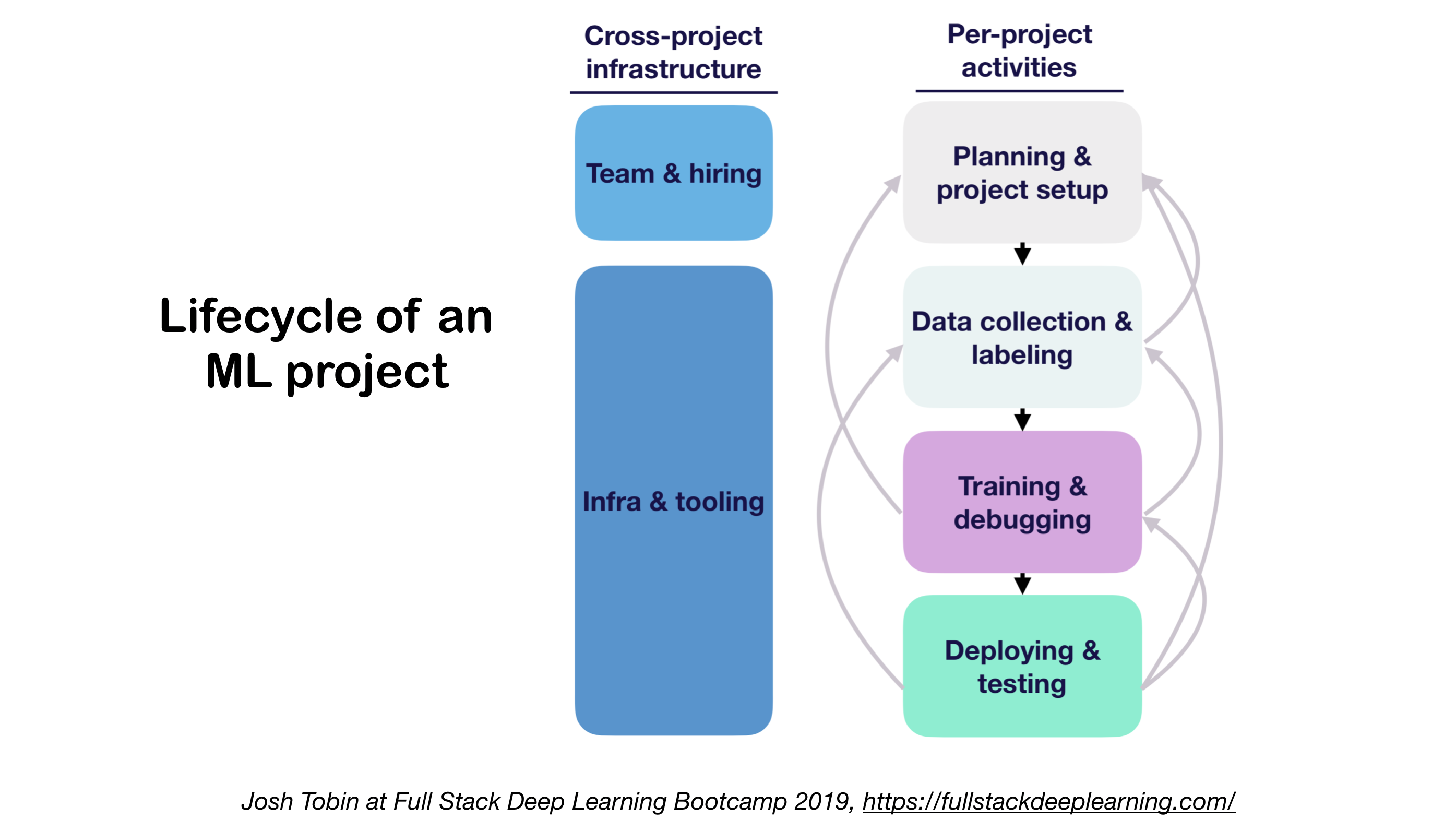
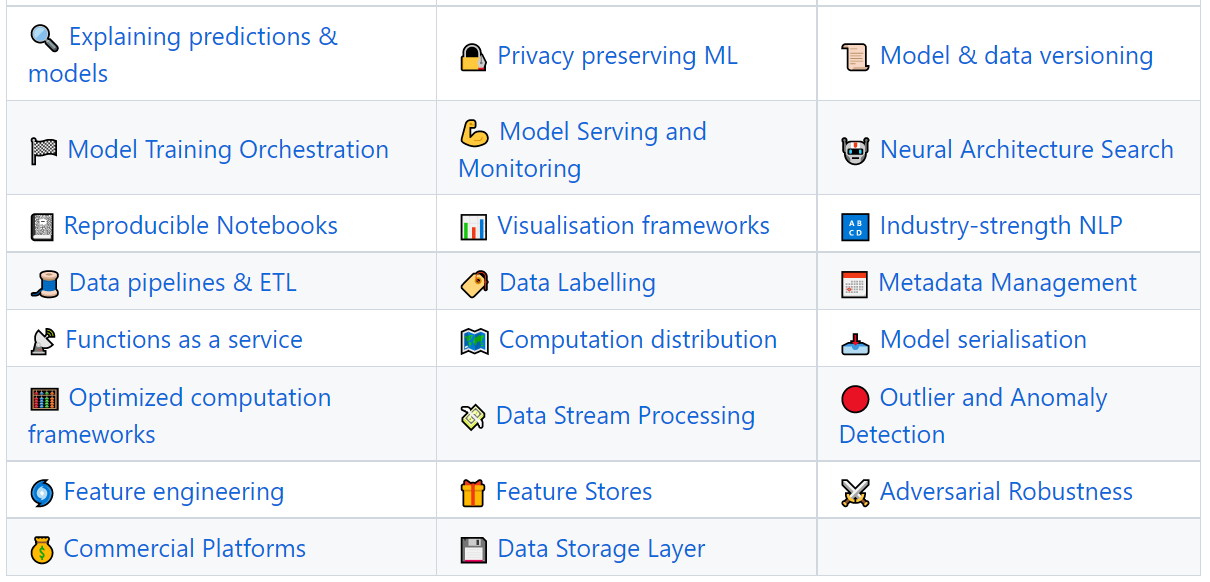
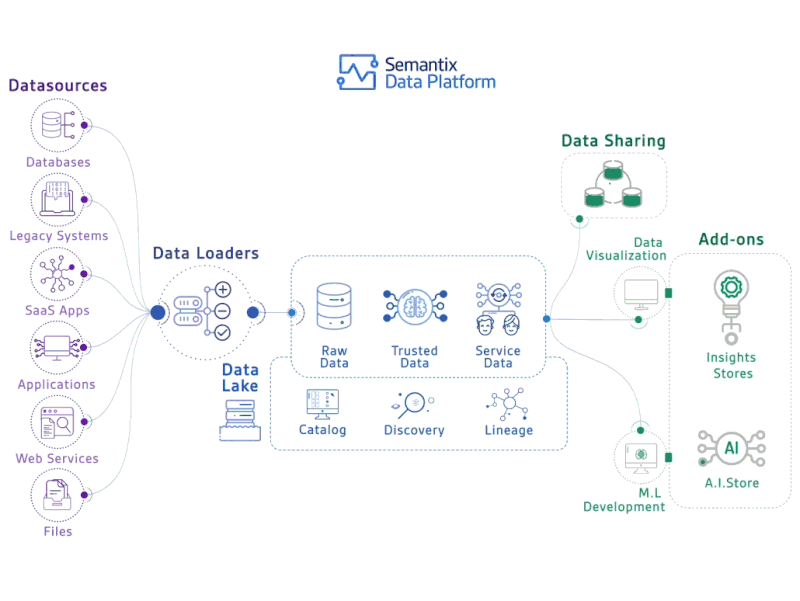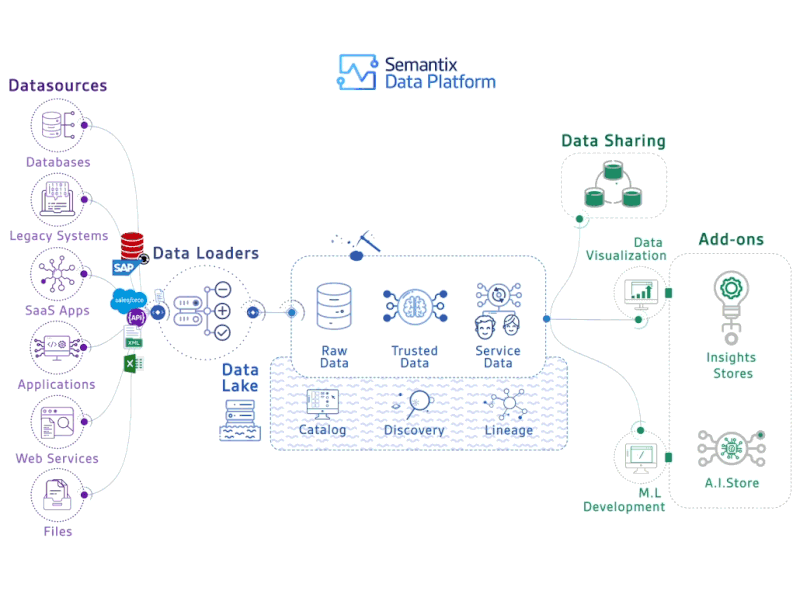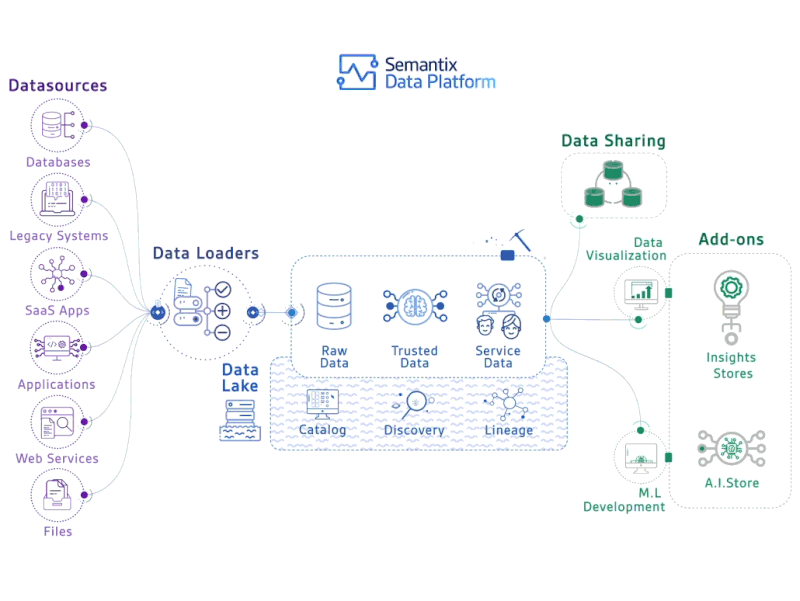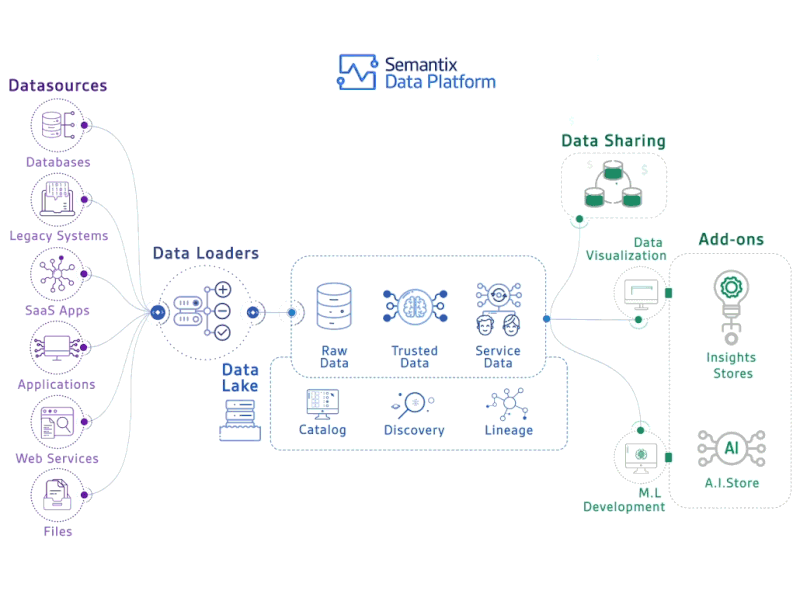
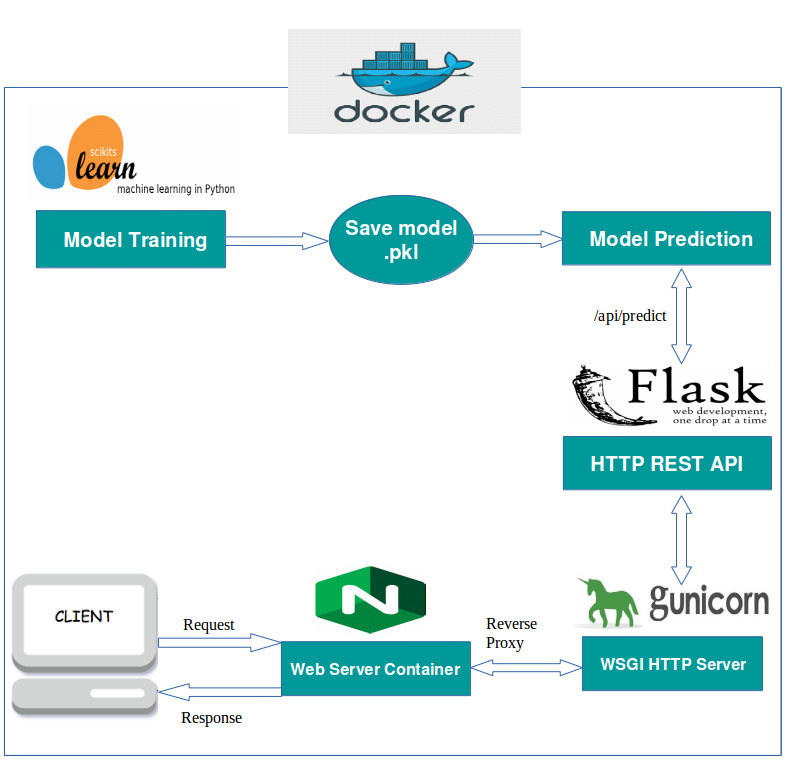
Deploying deep learning models in production can be challenging, as it is far beyond training models with good performance.
Several distinct components need to be designed and developed in order to deploy a production level deep learning system (seen below):
Link
This post is a simple tutorial for how to use a variant of BERT to classify sentences.
This is an example that is basic enough as a first intro, yet advanced enough to showcase some of the key concepts involved.
Link
This repository contains a curated list of awesome open source libraries that will help you deploy, monitor, version, scale, and secure your production machine learning.
Link
Software Engineering for Machine Learning are techniques and guidelines for building ML applications that do not concern the core ML problem – e.g. the development of new algorithms – but rather the surrounding activities like data ingestion, coding, testing, versioning, deployment, quality control, and team collaboration.
Good software engineering practices enhance development, deployment and maintenance of production level applications using machine learning components.
Link
BentoML is a flexible, high-performance framework for serving, managing, and deploying machine learning models.
Supports Multiple ML frameworks, including Tensorflow, PyTorch, Keras, XGBoost and more
Cloud native deployment with Docker, Kubernetes, AWS, Azure and many more
High-Performance online API serving and offline batch serving
Web dashboards and APIs for model registry and deployment management
Link
This organization contains software for realtime computer vision published by the members, partners and friends of the BMW TechOffice MUNICH and InnovationLab.
Link
1.Django + Vue + GraphQL + AWS Cookiecutter
2.Cookiecutter Pipeline for SAM based Serverless App
3.Cookiecutter Python Microservice
4.A cookiecutter template for bootstrapping a FastAPI and React project using a modern stack.
5.Cookiecutter for pyTorch
6.Cookiecutter for Data Science 1
7.Cookiecutter for Data Science 2
8.Cookiecutter for Data Science 3
Write ML Pipelines that will make your MLOps team happy: follow a clean separation of responsibility between model code and ops code. This article show you how to do that.
Link
EvalML is an AutoML library which builds, optimizes, and evaluates machine learning pipelines using domain-specific objective functions.
Key Functionality
Automation - Makes machine learning easier. Avoid training and tuning models by hand. Includes data quality checks, cross-validation and more.
Data Checks - Catches and warns of problems with your data and problem setup before modeling.
End-to-end - Constructs and optimizes pipelines that include state-of-the-art preprocessing, feature engineering, feature selection, and a variety of modeling techniques.
Streamlit enables data scientists and machine learning practitioners to build data and machine learning applications quickly.
In this piece, we will look at how we can use Streamlit to build a face verification application.
However, before we can start verifying faces, we have to detect them. In computer vision, face detection is the task of locating and localizing faces in an image. Face verification is the process of comparing the similarity of two or more images.