Modal lets you run or deploy machine learning models, massively parallel compute jobs, task queues, web apps, and much more, without your own infrastructure.
Link
OpenPose has represented the first real-time multi-person system to jointly detect human body, hand, facial, and foot keypoints (in total 135 keypoints) on single images.
Link
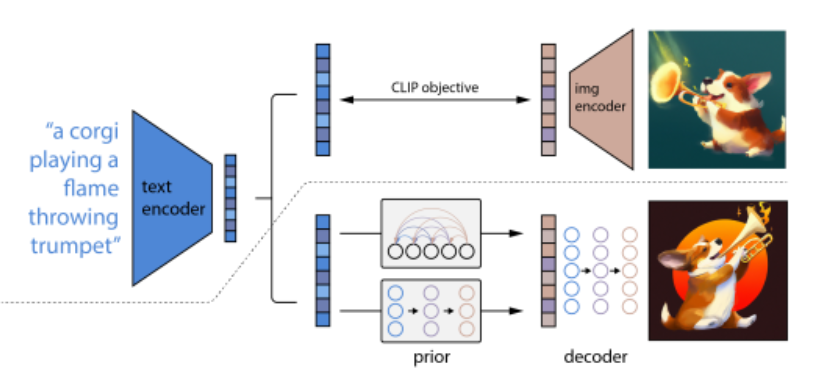
Text-to-image has advanced at a breathless pace in 2021 - 2022, starting with DALL·E, then DALL·E 2, Imagen, and now Stable Diffusion. I dug into a couple of papers to learn more about the space and organized my understanding into a few key concepts
Link
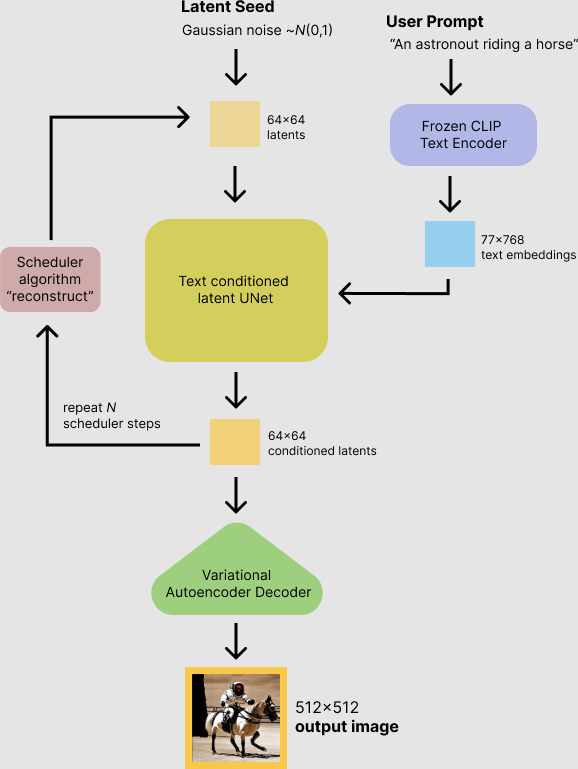
Stable Diffusion is a text-to-image latent diffusion model created by the researchers and engineers from CompVis, Stability AI and LAION. It is trained on 512x512 images from a subset of the LAION-5B database. LAION-5B is the largest, freely accessible multi-modal dataset that currently exists.
Link
This video presents our tutorial on Denoising Diffusion-based Generative Modeling: Foundations and Applications. This tutorial was originally presented at CVPR 2022 in New Orleans and it received a lot of interest from the research community.
Link
PYSKL is a toolbox focusing on action recognition based on SKeLeton data with PYTorch. Various algorithms will be supported for skeleton-based action recognition. We build this project based on the OpenSource Project MMAction2.
Link
Learn advanced computer vision using Python in this full course. You will learn state of the art computer vision techniques by building five projects with libraries such as OpenCV and Mediapipe. If you are a beginner, don’t be afraid of the term advance. Even though the concepts are advanced,
Link