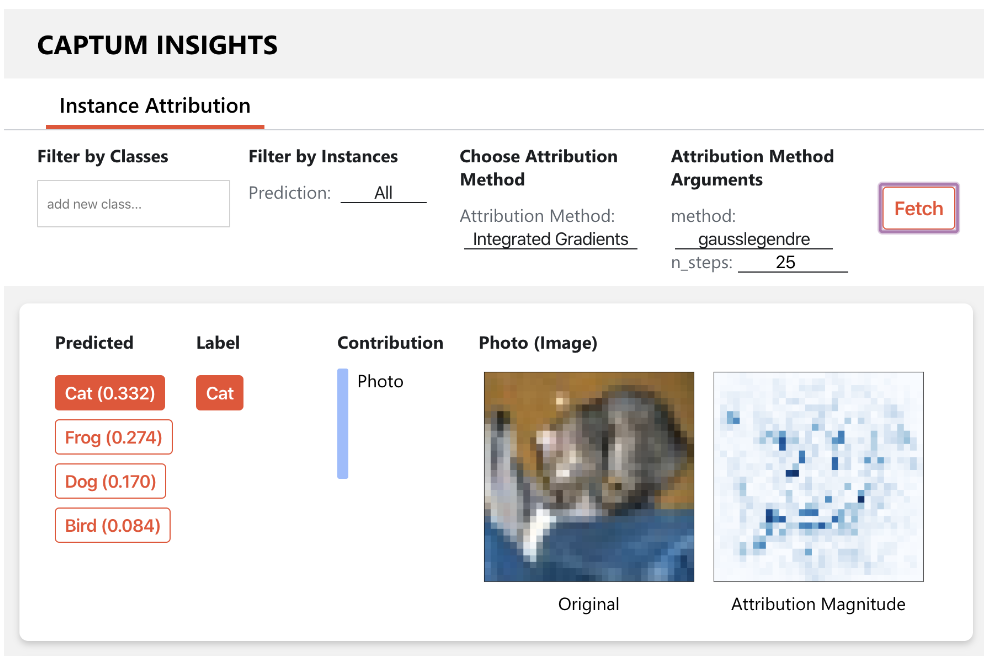
For data scientists and data engineers, d6tflow is a python library which makes building complex data science workflows easy, fast and intuitive. It is primarily designed for data scientists to build better models faster. For data engineers, it can also be a lightweight alternative and help productionize data science models faster. Unlike other data pipeline/workflow solutions, d6tflow focuses on managing data science research workflows instead of managing production data pipelines.
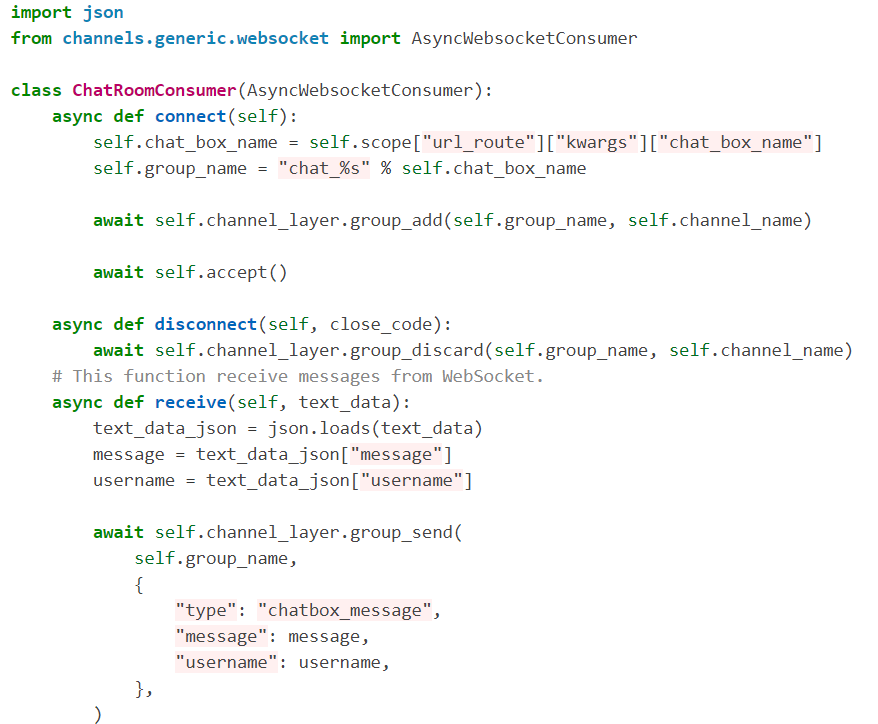
Building stateful web applications can be tricky, unless you use a framework, of course—Django to the rescue! In this article, learn how to build a realtime chat app using Django Channels and WebSockets.
Link
We dive into some of the internals of MLPs with multiple layers and scrutinize the statistics of the forward pass activations, backward pass gradients, and some of the pitfalls when they are improperly scaled. We also look at the typical diagnostic tools and visualizations you’d want to use to understand the health of your deep network. We learn why training deep neural nets can be fragile and introduce the first modern innovation that made doing so much easier: Batch Normalization.
Many web projects have moved to the single-page application model. To use this model with Django, you build a project where Django is the back end accessed through a REST API. The Django Ninja library is a FastAPI-inspired tool kit for turning Django views into REST API endpoints with very little extra code. Along the way, you’ll be using curl, a command-line tool that allows you to grab the contents of a web page.
GPU architectures are critical to machine learning, and seem to be becoming even more important every day. However you can be an expert in machine learning without ever touching GPU code. It is a bit weird to be work always through abstraction.
Link
DBT(data build tool) is a data transformation tool that enables data engineers and analysts to transform and document data. It provides the transformation layer in ELT(export-load-transform) process. It also facilitates how data professionals can build scalable and maintainable code just like software engineers.
Link
This is a collection of 16 tensor puzzles. Like chess puzzles these are not meant to simulate the complexity of a real program, but to practice in a simplified environment. Each puzzle asks you to reimplement one function in the NumPy standard library without magic.
Link
Kedro is an open-source Python framework for creating reproducible, maintainable and modular data science code. It borrows concepts from software engineering and applies them to machine-learning code; applied concepts include modularity, separation of concerns and versioning. Kedro is hosted by the LF AI & Data Foundation.
Link
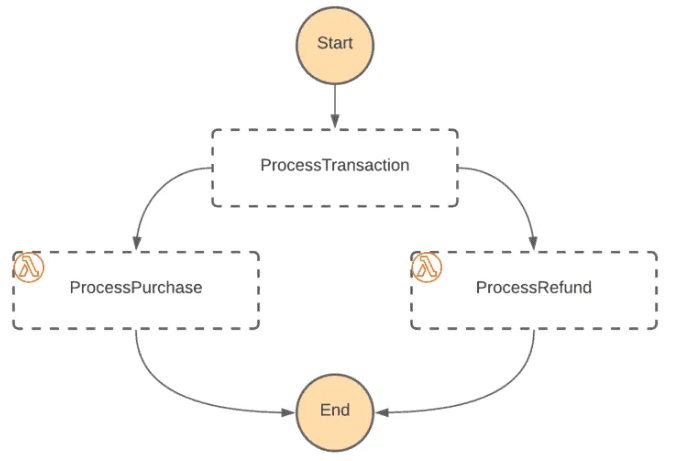
AWS Step Functions is a visual workflow service that allows you to orchestrate AWS services, automate business processes, and build serverless applications.
Link
Kinesis Data Stream is used to ingest real-time streaming data. Now such streaming data can be ingested to Amazon Redshift for the real-time analytics purpose. Learn how to integrate Kinesis Data Stream with Amazon Redshift.
Link
This post is a continuation of blog post “Developing AWS Glue ETL jobs locally using a container“. While the earlier post introduced the pattern of development for AWS Glue ETL Jobs on a Docker container using a Docker image, this post focuses on how to develop and test AWS Glue version 3.0 jobs using the same approach.
Link
This article will show how software development teams can build on-demand environments for dog-food testing, quality review and demos Link
terraform-aws-django
terraform-aws-ad-hoc-environments