Auto Merging Retriever Pack and Small-to-big Retrieval Pack provided by LlamaIndex perform the best for this experiment. Read on to see what went down
Link
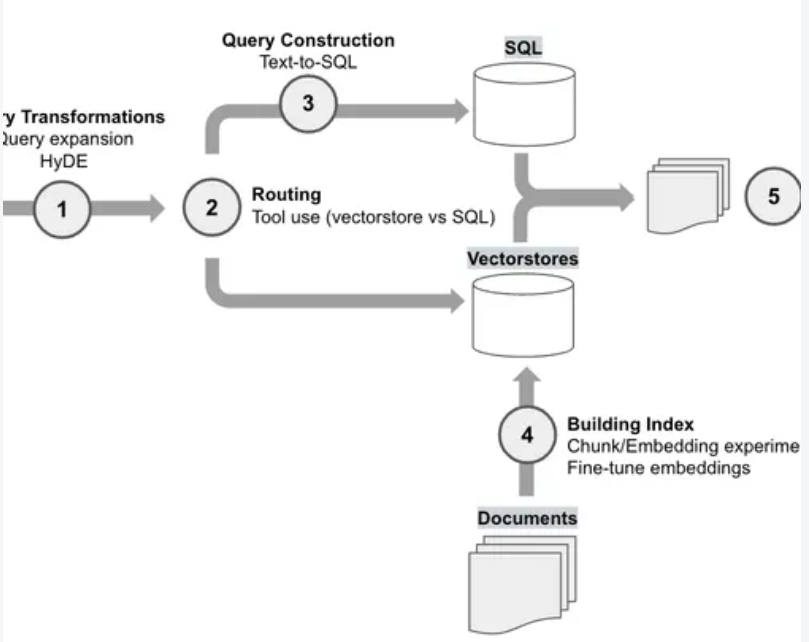
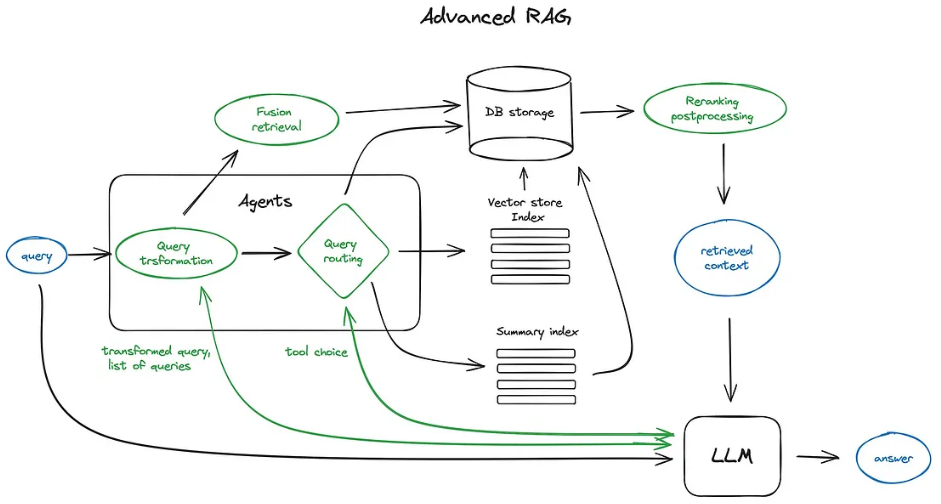
At their demo day, Open AI reported a series of RAG experiments for a customer that they worked with. While evaluation metics will depend on your specific application, it’s interesting to see what worked and what didn’t for them. Below, we expand on each method mention and show how you can implement each one for yourself. The ability to understand and these methods on your application is critical: from talking to many partners and users, there is no “one-size-fits-all” solution because different problems require different retrieval techniques.
The agent can produce detailed, factual and unbiased research reports, with customization options for focusing on relevant resources, outlines, and lessons. Inspired by the recent Plan-and-Solve and RAG papers, GPT Researcher addresses issues of speed, determinism and reliability, offering a more stable performance and increased speed through parallelized agent work, as opposed to synchronous operations.
Link
Building a Tavily Data Agent
research-assistan
Today we introduce Query Pipelines, a new declarative API within LlamaIndex that allows you to concisely orchestrate simple-to-advanced query workflows over your data for different use cases (RAG, structured data extraction, and more).
Link
Usage Pattern
Get your RAG application rolling in no time. Mix and match our Data Loaders and Agent Tools to build custom RAG apps or use our LlamaPacks as a starting point for your retrieval use cases.
Link
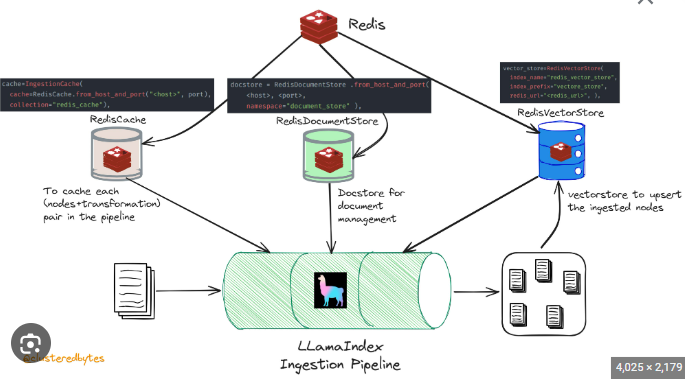
An IngestionPipeline uses a concept of Transformations that are applied to input data. These Transformations are applied to your input data, and the resulting nodes are either returned or inserted into a vector database (if given). Each node+transformation pair is cached, so that subsequent runs (if the cache is persisted) with the same node+transformation combination can use the cached result and save you time.
Link
LlamaPack
Here we chain together a full RAG pipeline consisting of query rewriting, retrieval, reranking, and response synthesis.
Here we can’t use chain syntax because certain modules depend on multiple inputs (for instance, response synthesis expects both the retrieved nodes and the original question). Instead we’ll construct a DAG explicitly, through add_modules and then add_link.
Link