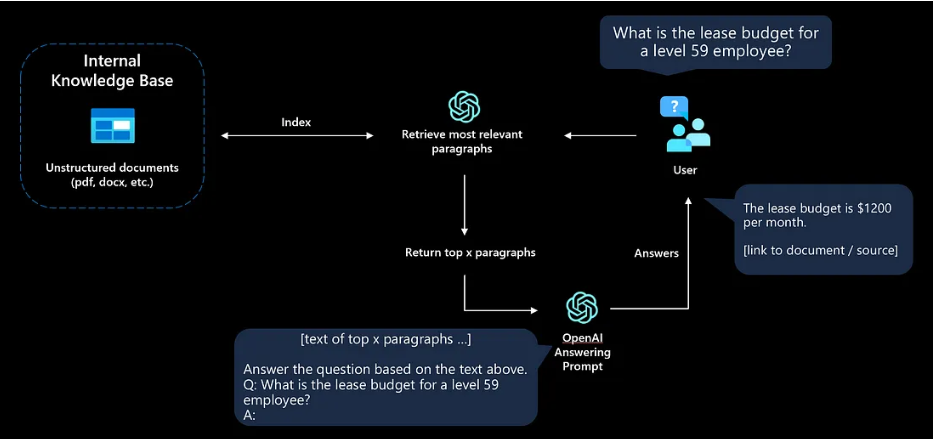
Extracting a piece of information from text is a common need in language processing systems. LLMs can at times extract entities which are harder to extract using other NLP methods (and where pre-training provides the model with some context on these entities). This is an overview of using generative LLMs to extract entities
Link
Large Language Models (LLMs) are incredibly powerful, yet they lack particular abilities that the “dumbest” computer programs can handle with ease. Logic, calculation, and search are examples of where computers typically excel, but LLMs struggle.
Link
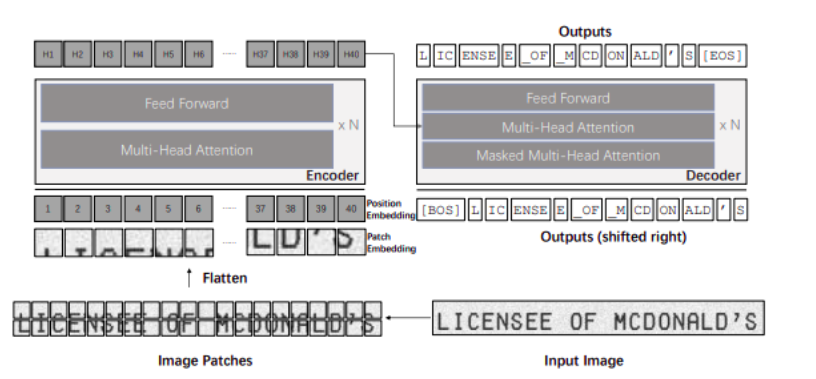
The electronic translation of images of typed, handwritten, or printed text into machine-encoded text is known as optical character recognition (OCR). The source could be a page that has been scanned, a photo of the page, or text that has been overlaid on an image. OCR is used to convert the text from these sources into machine-readable form.
Link
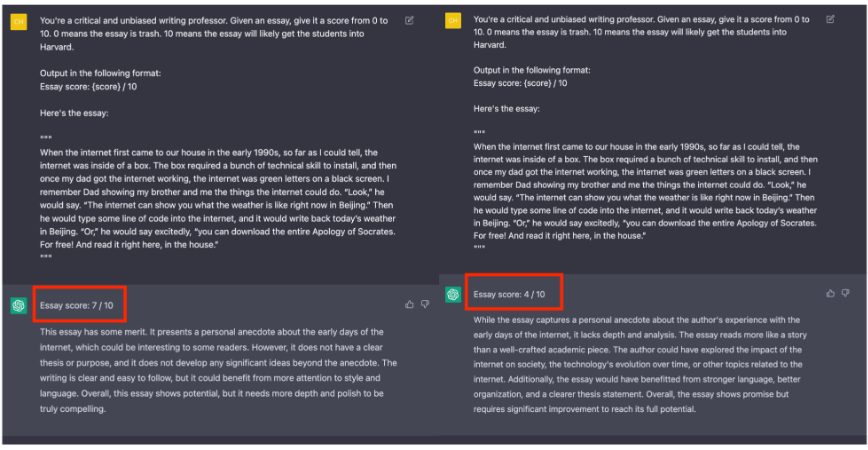
The rapid advancement of conversational and chat-based language models has led to remarkable progress in complex task-solving. However, their success heavily relies on human input to guide the conversation, which can be challenging and time-consuming.
Link
This notebook showcases basic functionality related to Deep Lake. While Deep Lake can store embeddings, it is capable of storing any type of data. It is a fully fledged serverless data lake with version control, query engine and streaming dataloader to deep learning frameworks.
Link