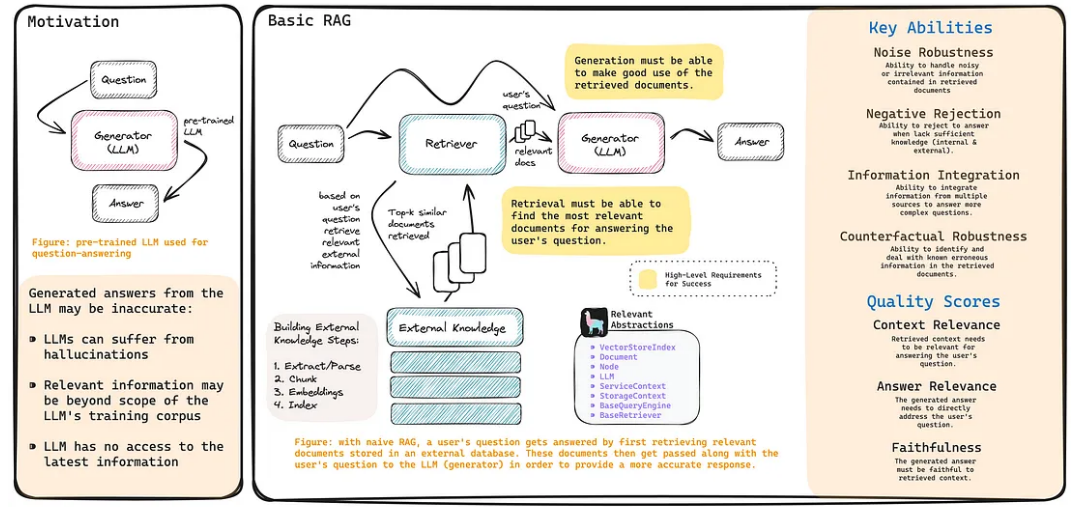
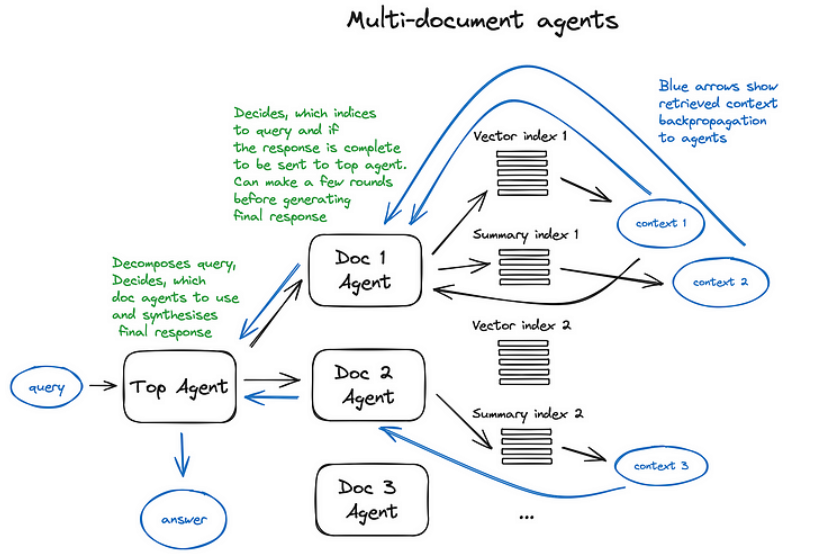
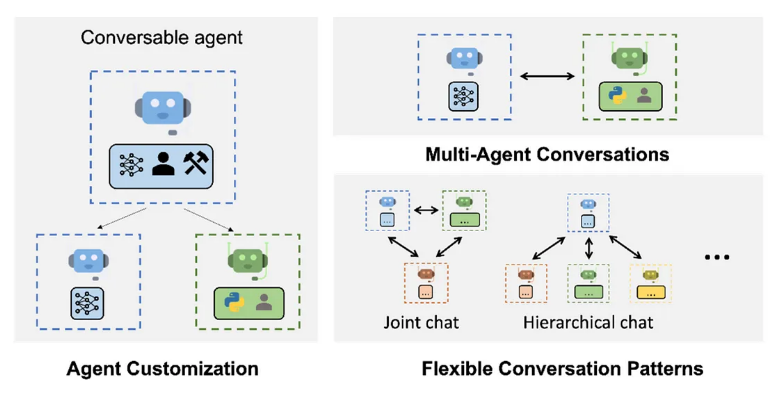
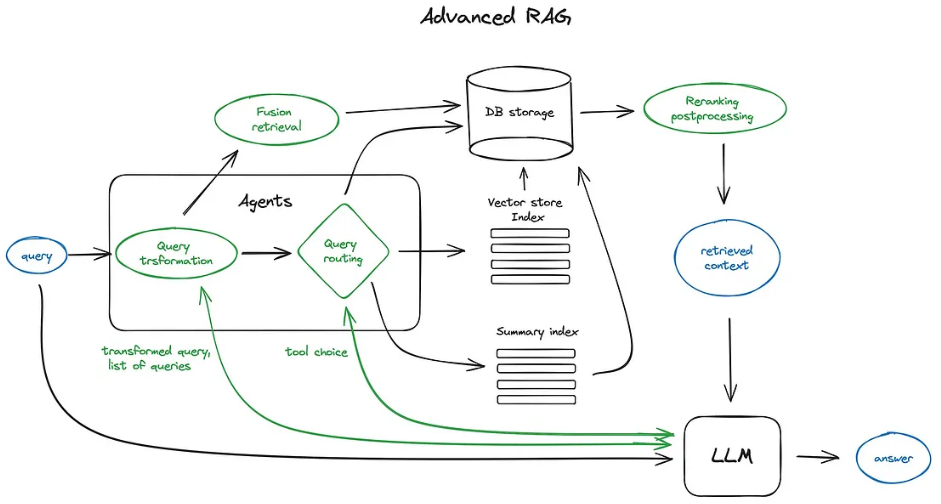
The RAG cheat sheet shared above was greatly inspired by a recent RAG survey paper (“Retrieval-Augmented Generation for Large Language Models: A Survey” Gao, Yunfan, et al. 2023).
Link
A comprehensive study of the advanced retrieval augmented generation techniques and algorithms, systemising various approaches. The article comes with a collection of links in my knowledge base referencing various implementations and studies mentioned.
Link
Auto Merging Retriever Pack and Small-to-big Retrieval Pack provided by LlamaIndex perform the best for this experiment. Read on to see what went down
Link
In the ever-evolving landscape of artificial intelligence (AI) and natural language processing (NLP), researchers and developers continue to push the boundaries of what’s possible. One such groundbreaking development is the Auto Generated Agent Chat, a cutting-edge system that employs Retrieval Augmented Generation (RAG) to transform group conversations. This technology combines the strengths of both retrieval-based and generative models, offering a unique and efficient solution for enhancing communication in group settings.
A Semantic Router is an advanced layer in the realm of chatbots and natural language processing. Think of it as a fuzzy yet deterministic interface layered over your chatbots or any system that processes natural language. Its primary function? To serve as a super-fast decision-making layer for Large Language Models (LLMs).
Link
How to store the conversation history in memory and include it within our prompt. How to transform the input question such that it retrieves the relevant information from our vector database.
Link
Today we introduce Query Pipelines, a new declarative API within LlamaIndex that allows you to concisely orchestrate simple-to-advanced query workflows over your data for different use cases (RAG, structured data extraction, and more).
Link
Usage Pattern
Example code for building applications with LangChain, with an emphasis on more applied and end-to-end examples than contained in the main documentation.
Link
In the intricate landscape of modern software development, orchestrating complex sequences of actions seamlessly poses a significant challenge. Enter LangChain Expression Language (LCEL), a groundbreaking declarative approach designed to revolutionize the composition of chains within software architecture.
Link
Prototyping a Retrieval-Augmented Generation (RAG) application is relatively straightforward, but the challenge lies in optimizing it for performance, robustness, and scalability across vast knowledge repositories. This guide aims to provide insights, strategies, and implementations leveraging LlamaIndex to enhance the efficiency of your RAG pipeline, catering to complex datasets and ensuring accurate query responses without hallucinations.
Link
Here we chain together a full RAG pipeline consisting of query rewriting, retrieval, reranking, and response synthesis.
Here we can’t use chain syntax because certain modules depend on multiple inputs (for instance, response synthesis expects both the retrieved nodes and the original question). Instead we’ll construct a DAG explicitly, through add_modules and then add_link.
Link