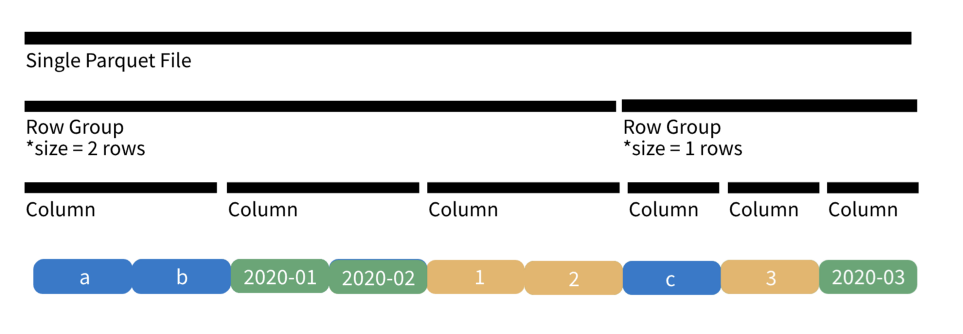
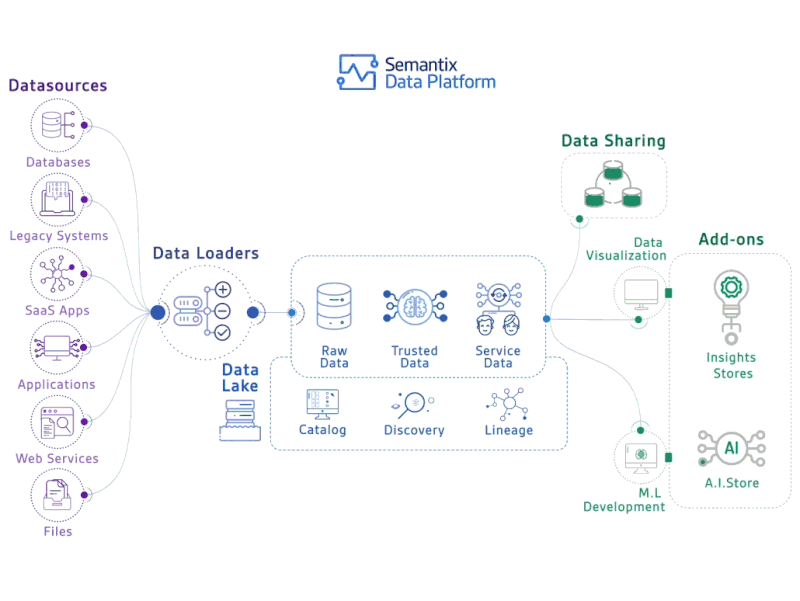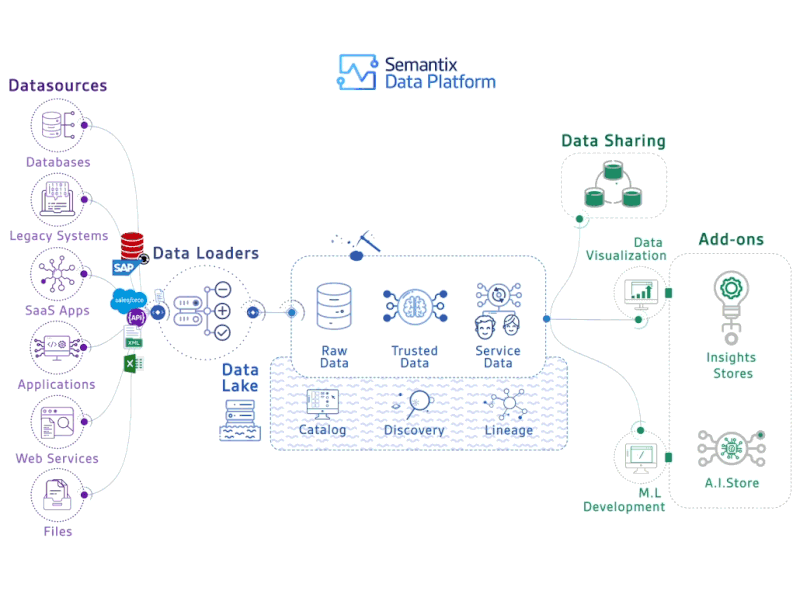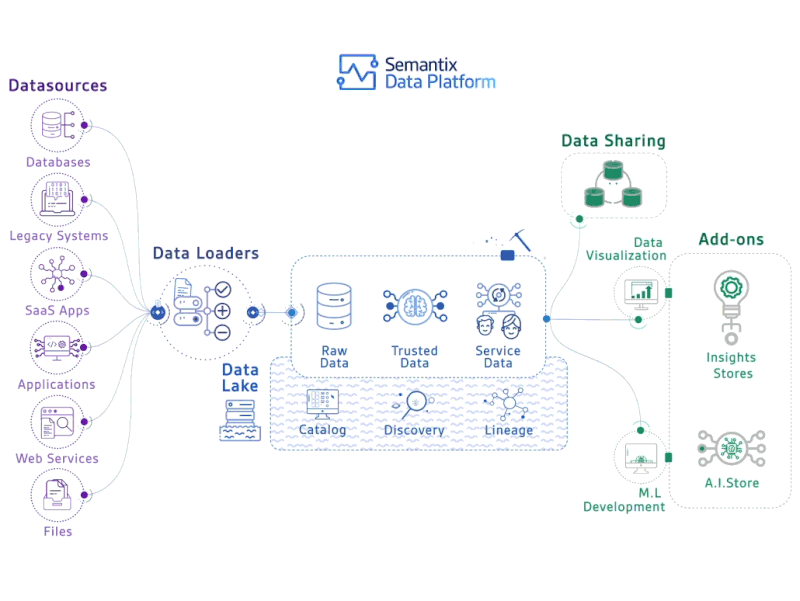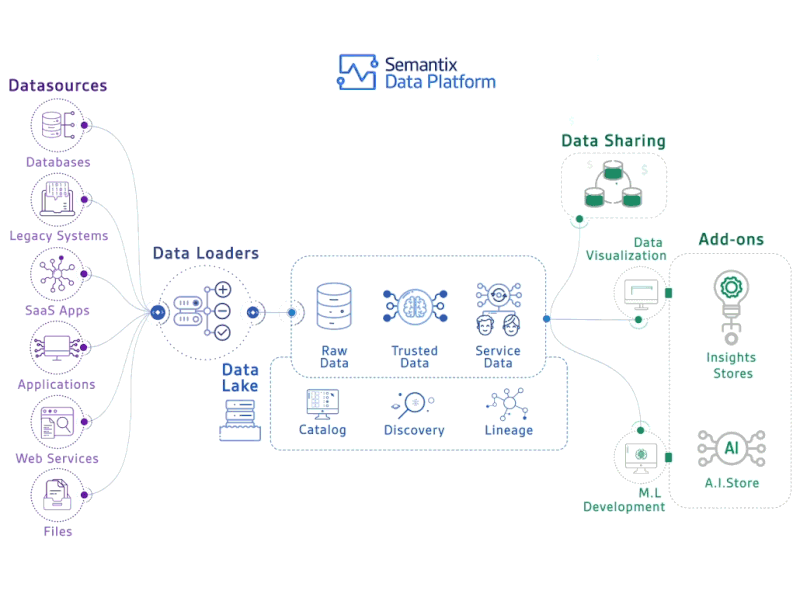
In this post we will discuss apache parquet, an extremely efficient and well-supported file format. The post is geared towards data practitioners (ML, DE, DS) so we’ll be focusing on high-level concepts and using SQL to talk through core concepts, but links for further resources can be found throughout the post and in the comments.
Link
Dask provides advanced parallelism for analytics, enabling performance at scale for the tools you love. This includes numpy, pandas and sklearn. It is open-source and freely available. It uses existing Python APIs and data structures to make it easy to switch between Dask-powered equivalents.
Vaex is a high-performance Python library for lazy Out-of-Core DataFrames (similar to Pandas), to visualize and explore big tabular datasets. It can calculate basic statistics for more than a billion rows per second.