Prototyping a Retrieval-Augmented Generation (RAG) application is relatively straightforward, but the challenge lies in optimizing it for performance, robustness, and scalability across vast knowledge repositories. This guide aims to provide insights, strategies, and implementations leveraging LlamaIndex to enhance the efficiency of your RAG pipeline, catering to complex datasets and ensuring accurate query responses without hallucinations.
Link
Here we chain together a full RAG pipeline consisting of query rewriting, retrieval, reranking, and response synthesis.
Here we can’t use chain syntax because certain modules depend on multiple inputs (for instance, response synthesis expects both the retrieved nodes and the original question). Instead we’ll construct a DAG explicitly, through add_modules and then add_link.
Link
In this article, we’ll introduce you to the innovative world of Autogen, an AI agent that’s revolutionizing how we fine-tune and customize large multimodal models. Autogen takes the complexity out of the equation by automating and simplifying the fine-tuning process, making it accessible to developers and researchers alike. We’ll explore how Autogen collaborates seamlessly with models like LLaVA, streamlining AI agent development and opening the doors to more efficient and precise AI-driven solutions.
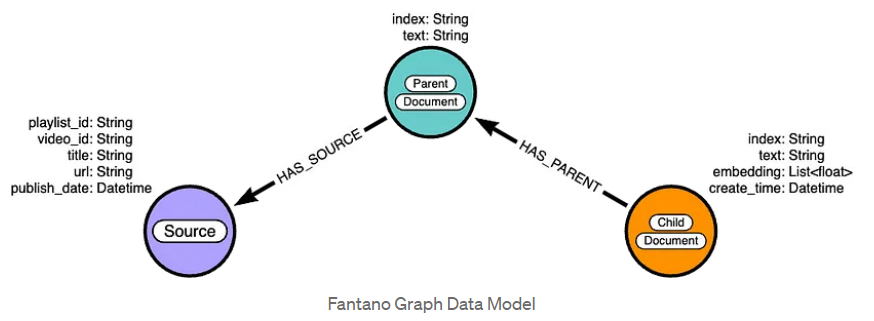
Here we will explore how to scrape YouTube video transcripts into a knowledge graph for Retrieval Augmented Generation (RAG) applications. We will use Google Cloud Platform to store our initial transcripts, LangChain to create documents from the transcripts and a Neo4j graph database to store the resulting documents. In this example we will be creating a knowledge graph containing objective musical facts spoken by Anthony Fantano himself on a select few music genres.
Large Language Models (LLMs) like OpenAI ChatGPT are called foundational models because even though they are trained for a relatively small set of tasks, they work exceptionally well for multiple unseen downstream tasks. While there is still some debate on how they are so good, at a high level it is quite easy to under what they do — they just predict the next word (read tokens). And all the cool tools you see built using these models, are nothing but the smart application of this feature.
Imagine you have a lot of text data inside your database. And you want to extract insights to analyze it or perform various AI tasks on text data. In this article, you will learn how to use MindsDB to integrate your database with OpenAI GPT-3 and get insights from all your text data at once with a few SQL commands instead of making multiple individual API calls, ETL-ing and moving massive amounts of data.
Finance NLP is a John Snow Lab’s product, launched 2022 to provide state-of-the-art, autoscalable, domain-specific NLP on top of Spark. With more than 100 models, featuring Deep Learning and Transformer-based architectures
Link